在之前的文章中,给大家介绍了《》,今天进一步给大家介绍为什么选择Key-Value Store。Key-Value Store是当下比较流行的话题,尤其在构建诸如搜索引擎、IM、P2P、游戏、SNS等大型互联网应用以及提供云计算服务的时候,怎样保证系统在海量数据环境下的高性能、高可靠性、高扩展性、高可用性、低成本成为所有系统架构们挖苦心思考虑的重点,而怎样解决数据库的性能瓶颈是最大的挑战。
大量的互联网用户选择Key-Value Store的原因具体是什么呢? 主要分为下面的2个主要原因:
1、大规模的互联网应用
对于google,ebay这样的互联网企业,每时每刻都有无数的用户在使用它们提供的互联网服务,这些服务带来的就是大量的数据吞吐量,在同一时间, 会并发的有成千上万的连接对数据库进行操作。在这种情况下,单台服务器或者几台服务器远远不能满足这些数据处理的需求,简单的升级服务器性能这样的 scale up的方式也不行,所以唯一可以采用的办法就是scale out了。scale out的方法有很多种,但大致分为两类:一类仍然采用RDBMS,然后通过对数据库的垂直和水平切割将整个数据库部署到一个集群上,这种方法的优点在于可 以采用RDBMS这种熟悉的技术,但缺点在于它是针对特定应用的,就是说,由于应用的不同,切割的方法是不一样的。
还有一类就是 google所采用的方法,抛弃RDBMS,采用key-value形式的存储,这样可 以极大的增强系统的可扩展性(scalability),如果要处理的数据持续增大,多加机器就 可以了。事实上,key-value的存储就是由于BigTable等相关论文的发表慢慢进入人们的 视野的。
2、云存储
如果说上一个问题还有可以替代的解决方案(切割数据库)的话,那么对于云存储来说,也许key-value的store就是唯一的解决方案了。云存储简 单点说就是构建一个大型的存储平台给别人用,这也就意味着在这上面运行的应用其实是不可控的。如果其中某个客户的应用随着用户的增长而不断增长时,云存储 供应商是没有办法通过数据库的切割来达到scale的,因为这个数据是客户的,供应商不了解这个数据自然就没法作出切割。在这种情况下,key- value的store就是唯一的选择了,因为这种条件下的scalability必须是自动完成的,不能有人工干预。这也是为什么几乎所有的现有的云存 储都是key-value形式的,例如Amazon的smipleDB,底层实现就是key-value,还有google的 GoogleAppEngine,采用的是BigTable的存储形式。也许唯一可能例外的是MS的解决方案,我在Qcon大会上听说MS的Azure平 台的下一个版本中就会推出基于RDBMS的云存储,尽管我本人仍然对此保持怀疑。
Key-Value Store最大的特点就是它的可扩展性,这也就是它最大的优势。所谓的可扩展性,在我看来这里包括了两方面内容。一方面,是指Key-Value Store可以支持极大的数据的存储,它的分布式的架构决定了只要有更多的机器,就能够保证存储更多的数据。另一方面,是指它可以支持数量很多的并发的查 询。对于RDBMS,一般几百个并发的查询就可以让它很吃力了,而一个Key-Value Store,可以很轻松的支持上千的并发查询。下面而简单的罗列了一些特点:
●Key-value store:一个 key-value 数据存储系统,只支持一些基本操作,如:SET(key, value) 和 GET(key) 等;
●分布式:多台机器(nodes)同时存储数据和状态,彼此交换消息来保持数据一致,可视为一个完整的存储系统。
●数据一致:所有机器上的数据都是同步更新的、不用担心得到不一致的结果;
●冗余:所有机器(nodes)保存相同的数据,整个系统的存储能力取决于单台机器(node)的能力;
●容错:如果有少数 nodes 出错,比如重启、当机、断网、网络丢包等各种 fault/fail 都不影响整个系统的运行;
●高可靠性:容错、冗余等保证了数据库系统的可靠性。
3、Redis实际应用案例
目前全球最大的Redis用户是新浪微博,在新浪有200多台物理机,400多个端口正在运行着Redis, 有+4G的数据跑在Redis上来为微博用户提供服务。
在新浪微博Redis的部署场景很多,大概分为如下的2种:
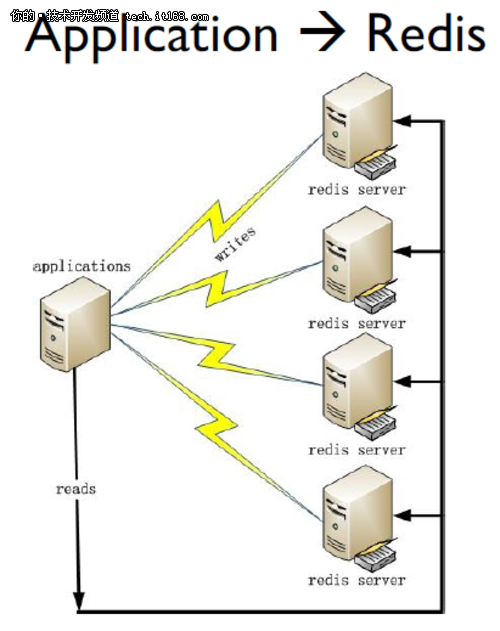
第一种是应用程序直接访问Redis数据库:
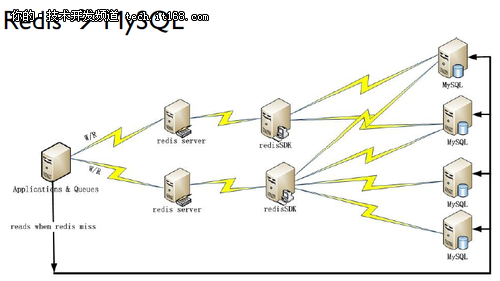
第二种是应用程序直接访问Redis,只有当Redis访问失败时才访问MySQL:
同时,Digg的一项新功能,添加了对文章浏览数的显示,这一功能的一大卖点是其实时性。而支持此实时浏览量计数的,正是Redis。